一.redis的集群之redis cluster的概念
对于Redis集群方案有好多种,基本常用的就是twemproxy,codis,redis cluster这三种解决方案。
本文介绍redis cluster。
上篇博文实现redis的高可用,针对的主要是master宕机的情况,我们发现所有节点的数据都是一样的,那么一旦数据量过大,redis也会存在效率下降的问题,redis3.0版本正式推出后,有效地解决了redis分布式方面的需求,当遇到单机内存,并发,流量等瓶颈时,可以采用Cluster架构方法达到负载均衡的目的。
redis使用中遇到的瓶颈
我们日常在对于redis的使用中,经常会遇到一些问题
- 1、容量问题,单实例redis内存无法无限扩充,达到32G后就进入了64位世界,性能下降。
- 2、并发性能问题,redis号称单实例10万并发,但也是有尽头的。
redis-cluster的优势
-
1、官方推荐,毋庸置疑。
-
2、去中心化,集群最大可增加1000个节点,性能随节点增加而线性扩展。
-
3、管理方便,后续可自行增加或摘除节点,移动分槽等等。
-
4、简单,易上手。
redis-cluster名词介绍
- 1、master 主节点、
- 2、slave 从节点
- 3、slot 哈希槽,一共有16384数据分槽,分布在集群的所有主节点中。
redis-cluster的设计
Redis集群搭建的方式有多种,例如使用zookeeper等,但从redis 3.0之后版本支持redis-cluster集群,Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有 节点连接。其redis-cluster架构图如下:

图中描述的是六个redis实例构成的集群
- 6379端口为客户端通讯端口
- 16379端口为集群总线端口
集群内部划分为16384个数据分槽,分布在三个主redis中。
从redis中没有分槽,不会参与集群投票,也不会帮忙加快读取数据,仅仅作为主机的备份。
三个主节点中平均分布着16384数据分槽的三分之一,每个节点中不会存有有重复数据,仅仅有自己的从机帮忙冗余。
其结构特点:
-
1、所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
-
2、节点的fail是通过集群中超过半数的节点检测失效时才生效。
-
3、客户端与redis节点直连,不需要中间proxy层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
-
4、redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster
负责维护node<->slot<->value。 -
5、Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod16384的值,决定将一个key放到哪个桶中
。
redis cluster节点分配
假设我们现在有三个主节点,分别是:A, B, C 三个节点,它们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么,采用哈希槽
(hash slot)的方式来分配16384个slot 的话,它们三个节点分别承担的slot 区间是:节点A覆盖0-5460; 节点B覆盖5461-10922; 节点C覆盖10923-16383。获取数据:
如果存入一个值,按照redis cluster哈希槽的算法: CRC16(‘key’)%16384 = 6782。
那么就会把这个key 的存储分配到 B
上了。同样,当我连接(A,B,C)任何一个节点想获取’key’这个key时,也会这样的算法,然后内部跳转到B节点上获取数据。新增一个主节点:
新增一个节点D,redis
cluster的这种做法是从各个节点的前面各拿取一部分slot到D上,我会在接下来的实践中实验。大致就会变成这样:节点A覆盖1365-5460 节点B覆盖6827-10922 节点C覆盖12288-16383 节点D覆盖0-1364,5461-6826,10923-12287同样删除一个节点也是类似,移动完成后就可以删除这个节点了。
Redis Cluster主从模式
redis cluster
为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉。上面那个例子里,集群有ABC三个主节点,,如果这3个节点都没有加入从节点,如果B挂掉了,我们就无法访问整个集群了。A和C的slot也无法访问。 所以我们在集群建立的时候,一定要为每个主节点都添加了从节点, 比如像这样,,集群包含主节点A、B、C,,以及从节点A1、B1、C1,那么即使B挂掉系统也可以继续正确工作。 B1节点替代了B节点,所以Redis集群将会选择B1节点作为新的主节点,集群将会继续正确地提供服务。 当B重新开启后,它就会变成B1的从节点。 不过需要注意,如果节点B和B1同时挂了,Redis集群就无法继续正确地提供服务了。
一.redis的集群之redis cluster的配置
节点准备(官方推荐三主三从的配置方式。)
redis3.0及以上版本实现,集群中至少应该有奇数个节点,所以至少有三个节点,每个节点至少有一个备份节点,所以下面使用6节点(主节点、备份节点由redis-cluster集群确定)。
实验步骤如下所示:
第一步:停掉redis服务并创建目录
停掉redis服务(redis服务本身监听的端口是6379端口)
创建目录,用于存放redis Cluster对应的节点配置文件
[root@server1 ~]# /etc/init.d/redis_6379 stop
[root@server1 ~]# mkdir /usr/local/rediscluster
[root@server1 ~]# cd /usr/local/rediscluster/
[root@server1 rediscluster]# mkdir 700{1..6}
[root@server1 rediscluster]# ls
7001 7002 7003 7004 7005 7006

第二步:编写redis Cluster对应的节点的配置文件,并启动redis Cluster对应的所有节点
编辑配置文件,下面给出的是一个节点7001的配置文件(其余节点(7002-7006)的配置文件跟这个配置文件类似,只需要将其中的7001改为对应的节点即可)
[root@server1 rediscluster]# cd 7001/
[root@server1 7001]# vim redis.conf
port 7001 #端口
cluster-enabled yes #如果是yes,表示启用集群,否则以单例模式启动
cluster-config-file nodes.conf #请注意,尽管有此选项的名称,但这不是用户可编辑的配置文件,而是Redis群集节点每次发生更改时自动保留群集配置(基本上为状态)的文件,以便能够 在启动时重新读取它。 该文件列出了群集中其他节点,它们的状态,持久变量等等。 由于某些消息的接收,通常会将此文件重写并刷新到磁盘上。
cluster-node-timeout 5000 #Redis群集节点超过不可用的最长时间,而会将其视为失败。 如果主节点超过指定的时间不可达,它将由其从属设备进行故障切换。 此参数控制Redis群集中的其他重要事项。 值得注意的是,每个无法在指定时间内到达大多数主节点的节点将停止接受查询。
appendonly yes #是否开启appendonlylog,开启的话每次写操作会记一条log,这会提高数据抗风险能力,但影响效率。
daemonize yes #打入后台
[root@server1 7001]# redis-server redis.conf #启动7001节点

在7002/7003/7004/7005/7006/里面也是一样的操作,记得对应的目录就是文件里面写的端口

 7004/7005/7006这里就不一一展示了。
7004/7005/7006这里就不一一展示了。
查看所有端口:

第三步:创建集群(集群中的主从节点是随机的)
节点全部启动后,每个节点目前只能识别出自己的节点信息,彼此之间并不知道对方的存在;
实现集群的快速搭建,需要使用redis-cluster来创建集群,过程如下:
[root@server1 ~]# redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 #输入yes
# 使用create命令创建集群 --replicas 1 参数表示为每个主节点创建一个从节点,其他参数是实例的地址集合。
创建过程中会给出主从节点角色分配的计划,如下图所示
 最终可以看到:(当然下面的信息,也可以登录每个节点(例如:redis-cli -p 7001),查看每个节点的info replication,来获取)
最终可以看到:(当然下面的信息,也可以登录每个节点(例如:redis-cli -p 7001),查看每个节点的info replication,来获取)
- (1)主节点:7001;对应的从节点为:7005
- (2)主节点:7002;对应的从节点为:7006
- (3)主节点:7003;对应的从节点为:7004
可以使用下面的命令进行帮助:
[root@server1 ~]# redis-cli --cluster help #在使用redis-cli --cluster命令之前,可以先查看下redis-cli --cluster命令的帮助

此时可以利用下面的命令来查看该集群的主节点:
[root@server1 bin]# redis-cli --cluster info 127.0.0.1:7001
 也可以用下面这个命令查看该集群的具体信息:
也可以用下面这个命令查看该集群的具体信息:
[root@server1 bin]# redis-cli --cluster check 127.0.0.1:7001

redis集群的测试:测试存取值
客户端连接集群redis-cli需要带上 -c
redis-cli -c -p 端口号
redis-cli -c -p 7001
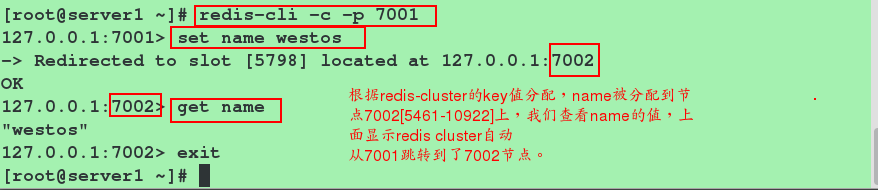
我们可以测试一下7004从节点获取name值

在7002节点获取name值,发现不会跳转
 结论:
结论:
自动跳转至7002获取值,这也是redis cluster的特点,它是去中心化,每个节点都是对等的,连接哪个节点都可以获取和设置数据。
redis cluster集群的故障迁移
(1)并手动将7002节点挂掉
 查看进程
查看进程

再次查看集群的信息,可以看到7006节点(之前7002节点的从节点)已经成为主节点。查看7006节点的所有key,可以看出7006节点承担着7002节点的角色。对外提供的服务不受影响



但是此时,如果将7006节点也手动down掉,那么该集群也就费了,因为至少三个master。

为了恢复数据,我们需要恢复7006(只能恢复master,因为从节点没变更一次,就会把数据flush掉),我们进入7006的目录,可以查看数据文件。

查看进程
 查看master节点
查看master节点

此时我们可以看到7006没有从节点

登录7001获取name值,可以获取到,会跳转到7006

总结:当master坏掉,但是数据文件没有丢失的话,我们恢复好master后,依旧可以看到数据。




